Note
Click here to download the full example code
Ninth Example: # GridSearch on dynamically built component using input signal values¶
- We continue demonstrating several interesting features:
- How the user can choose to encapsulate several blocks into a PipeGraph and use it as a single unit in another PipeGraph
- How these components can be dynamically built on runtime depending on initialization parameters
- How these components can be dynamically built on runtime depending on input signal values during fit
- Using GridSearchCV to explore the best combination of hyperparameters
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.preprocessing import MinMaxScaler
from sklearn.mixture import GaussianMixture
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
from pipegraph.base import ( PipeGraph,
RegressorsWithDataDependentNumberOfReplicas,
NeutralRegressor,
)
X_first = pd.Series(np.random.rand(100,))
y_first = pd.Series(4 * X_first + 0.5*np.random.randn(100,))
X_second = pd.Series(np.random.rand(100,) + 3)
y_second = pd.Series(-4 * X_second + 0.5*np.random.randn(100,))
X_third = pd.Series(np.random.rand(100,) + 6)
y_third = pd.Series(2 * X_third + 0.5*np.random.randn(100,))
X = pd.concat([X_first, X_second, X_third], axis=0).to_frame()
y = pd.concat([y_first, y_second, y_third], axis=0).to_frame()
X_train, X_test, y_train, y_test = train_test_split(X, y)
Now we consider the possibility of using the classifier’s output to automatically adjust the number of replicas. This can be seen as PipeGraph changing its inner topology to adapt its connections and steps to other components context. This morphing capability opens interesting possibilities to explore indeed. To ease the calculation of the score for the GridSearchCV we add a neutral regressor as a last step, capable of calculating the score using a default scoring function. This is much more convenient than worrying about programming a custom scoring function for a block with an arbitrary number of inputs.
scaler = MinMaxScaler()
gaussian_mixture = GaussianMixture(n_components=3)
models = RegressorsWithDataDependentNumberOfReplicas()
neutral_regressor = NeutralRegressor()
steps = [('scaler', scaler),
('classifier', gaussian_mixture),
('models', models),
('neutral', neutral_regressor)]
connections = {'scaler': {'X': 'X'},
'classifier': {'X': 'scaler'},
'models': {'X': 'scaler',
'y': 'y',
'selection': 'classifier'},
'neutral': {'X': 'models'}
}
pgraph = PipeGraph(steps=steps, fit_connections=connections)
Using GridSearchCV to find the best number of clusters and the best regressors
from sklearn.model_selection import GridSearchCV
param_grid = {'classifier__n_components': range(2,10)}
gs = GridSearchCV(estimator=pgraph, param_grid=param_grid, refit=True)
gs.fit(X_train, y_train)
y_pred = gs.predict(X_train)
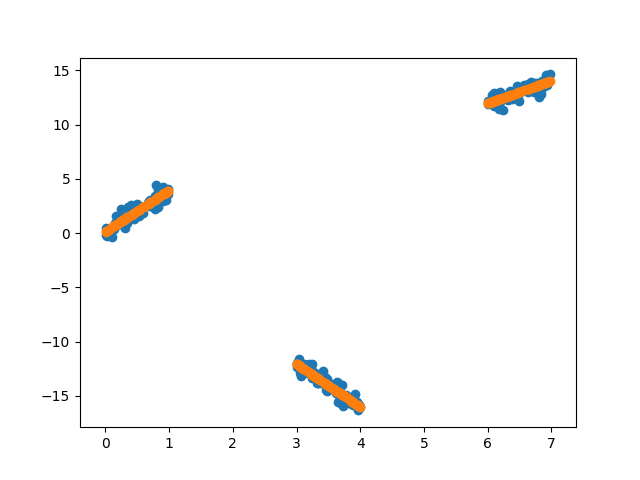
plt.scatter(X_train, y_train)
plt.scatter(X_train, y_pred)
print("Score:" , gs.score(X_test, y_test))
print("classifier__n_components:", gs.best_estimator_.get_params()['classifier__n_components'])
Out:
ERROR: _predict call ValueError!
ERROR: _predict call ValueError!
ERROR: _predict call ValueError!
Score: 0.9981733601419757
classifier__n_components: 3
Total running time of the script: ( 0 minutes 1.331 seconds)